
Comprehensive cloud automation for lazy control freaks.
Sourceforge Project PageAuthor: Geoff Howland (geoff.at.gmail.dot.com)
NOTE: This document uses capitalization, like proper nouns, when using REM terminology, to denote that the capitalized word has a special REM meaning. So a Hardware Port is a REM concept, and a hardware port is a non-REM concept. By intention REM terms will always be capitalized, but until this document has been heavily reviewed prepare to use context where it might be confusing to discern the meaning of terminology.

Total Systems Automation (TSA, the good kind), is a new approach to system administration. The defining difference between TSA and traditional system administration is that systems managed under a TSA approach will not require human involvement in any of the day-to-day administration of systems.
Humans will be involved in planning for what the system will look like, how the system will be built, how to inspect how the system is functioning (correctness and performance), what failures to look out for, and how to respond to return the system to a correct and properly performing state. Humans are required to write the scripts and verify the results, and then the machines and the TSA system will carry out the scripts, which if set up correct, will automate the daily administration needs of the machines.
If a TSA system is built correctly, then as usage of the system increases, the system will automatically respond by adding more machines and resources to accommodate the usage, without human intervention. Additionally if there are failures in the system, whether invoked by humans (rogue system administrators subverting the TSA system, or attackers) or hardware failures (systems or storage), then the TSA system should take steps to automatically correct the problem to immediately return the system to a working state, and alert humans that it is going on in specified manner, based on the humans best planning on how and when humans should learn about and get involved with running system issues.
A TSA system is not meant to eliminate system administrators, it is meant to raise the work the system administrators work on to planning for growth, planning for problems, and planning for how to respond to problems once they have come up, in as many layers deep as seem to be worth trying to fix in an automated fashion. TSA systems are a "plan, not pray" method of ensuring problems are found and corrected as quickly as possible, or in case it cant be automated, that the correct people are contacted, and in the correct order, with an acknowledgement system to know who to pass off next and a comprehensive support scheduling system.
With the availability of "Cloud Computing" ISPs, such as Amazon, TSAs become available to the public who would normally not be able to maintain a large pool of hardware, and shift broken components out of the working component pool, and have staff to manage them without interfering with their automation of provisioning, configuration, operation, scaling and repairs. Opportunities for automating the majority of systems operations is now available to all sizes of businesses.

It is worth noting that the service that Amazon and others are providing and labeling as "Cloud Computing", are better understood as "Utility Computing", which is buying computer, network and storage resources in the way you might buy gas and electricity as a resource. A centralized provider makes available resources that can be paid for monthly/hourly, as the resource is needed. This is not an academic or semantic argument, but intended to highlight that Cloud Computing is a vague and overloaded term, like Web 2.0, and while I will use it, I will use Utility Computing to refer to the specific function of being able to rent computing resources.
Utility Computing seems to very accurately describe what we can purchase from Amazon. Hourly and monthly payments for machine and storage, as we request, available on request, and terminatable on request as well.
So what is Cloud Computing? Cloud Computing is much more of a vague concept, but the idea of a "Cloud" leads one to think that it doesn't matter where the resources are, they are "in the cloud", and can move around "in the cloud", so their non-fixed locations seem to be a big factor in thinking about Cloud Computing.
Looking at Amazon's EC2 as Cloud Computing, can we really not care where machines are, because they are "in the cloud"? No. Amazon has region based requirements, such as Elastic Block Storage (EBS) devices must be in the same Availability Zone (region/data center) as the system instance that mounts them. On loss of an Availability Zone, or change of requirements for another machine outside that Zone, the storage may not be mounted on a new system instance in another Zone. Instead the storage must have a snapshot made, and then we must create a restored snapshot as a new EBS volume in the new Zone.
This does not jive with the concept of "things are in the cloud", but aligns very highly with Utility Computing, where we can purchase computing resources in regions, that have their rational corresponding limitations because they are running on real pieces of hardware in those regions.
Additionally, Cloud Computing providers, like Amazon, do not currently make all of these things transparent, though that may be their end-goal as they role out new services, but there is a difficult problem of trusting the vendor who provides you with computing resources to also handle all the management of those resources. All our eggs are in one basket. It is their responsibility to keep up the resources, their responsibility to come up with a design for making sure they stay available, and their responsibility for tracking everything is working properly.
This is a lot of responsibility for a vendor, and for most companies, will be greater than ever given to a vendor before.
Many companies probably like the sound of this. Offloading the problem to Amazon, who is clearly good at running their own large web site and building data centers and then selling overage usage to others as an additional business, creates a complete and total dependency on Amazon for your business.
However, Amazon only cares about our business functioning as a result of wanting payment for the resources, and good PR for others to pay for their resources. Their interest in our business's continuity ends there, and they are not liable nor do they indemnify us for failures in running our system on their resources, that is our concern (though I am not maligning their customer support or interest in providing the best service possible, just stating the obvious limitation in their concerns compared to ours).
This is not a negative that is so overwhelming as to discourage anyone from using Cloud Computing vendors, it should merely be understood as one of the risks. Just as there are risks in having a single data center provider, it is a factor of how much money your operational uptime and responsiveness is worth to your business. If it is not worth the money to care about Amazon's outages and gaps in their operational plans, as they relate to our operations, then 100% investment in their solutions may be a viable strategy.
If our operations are more important to us, and outages at the hands of vendors are not acceptable, then more needs to be done. Utility Computing is extremely useful, but does not provide the free-flowing goodness we expected when things are "in the cloud", and just seem to magically work.

Since Cloud Computing is not very well defined, and has an air of hand waving about it, it makes for great journalism and water cooler discussions, but is a poor marker for coming up with concrete plans to use Utility Computing resources. Additionally, very few large organizations will work solely in the cloud, or should for a number of reasons.
Also, using any single cloud vendor, like Amazon EC2, while they are good enough to be a primary cloud computing resource, leads to being locked in and caught whenever they have wide scale problems, come under siege from massive hacking efforts, does not provide competition on price, resources or support, can have resource shortages from being popular and highly used, and many more potential problems. A robust cloud computing plan should include having multiple cloud vendors, to ensure the ability to scale resources when your primary vendor is failing to meet your requirements.
Mixing in privately owned, non-cloud vendor resources, and treating them like they were also cloud resources, but with the benefit of being physical hardware that can be managed exactly as you wish, with the performance characteristics you can specify through explicitly purchasing hardware would be a powerful addition to a more comprehensive and integrated cloud computing environment.
This is the goal of a Service Centric system, where the goal of the system is to provide defined services, that can run on a number of different resources, both local to your offices, in rented data center space, leased machines in data centers, and from multiple cloud vendors.
The definitions of the services will determine which resources are assigned, in each location, to provide the service your users and applications require.
Combining this with a TSA system allows comprehensive planning of how to use these different pools of resources, how to combine them together, and take into account the variety of problems with security and data migration, backups, monitoring, failure response, and automated scaling.
This is the goal of the Red Eye Monitor (REM) system. To provide a method of defining the goals we want to provide in services, and then through a combination of owned/leased physical hardware in various regions, and rented virtual resources from various vendors in various regions, to fulfill your organizations needs in a planned and automated fashion.
This is not magic, and requires a greater deal of up-front work and planning, so whether you wish to embark on this system will come down to how you would like to approach your work.
The difference between using a TSA system and not, is that a TSA system starts off automated from the beginning, and is always an automated system. A non-TSA system starts off manually or semi-automated, and will likely always require a good deal of manual or automation re-architecting and re-working, as the ecosystem changes many of the automations will no longer work, and will need to be redone. With a TSA system, change is expected and planned for, so the general automation of the system never changes, only new hardware types need to be wrapped, new and updated packages versioned, and new business goals to be planned for, and additional levels of failure response automation can be added as it is deemed worth the trade off. Updating of the TSA system itself is planned for, so change management is included as a process to making changes to the TSA system, as this is a crucial part of Total Systems Automation.
A TSA system should lead to a much easier system to scale and manage, and will adapt to changes with minimal effort, but it requires a significant amount of expertise and effort to initially configure.

The REM system is a hierarchy, where everything springs forth from a Site, which allows a single REM installation to handle many separate systems, as distinct Sites, which can either interact with each other, or remain completely separate. User access can be different between these Sites so that they be managed separately, while still retaining authoritative information about each other.
One important hierarchy is the Hardware Computer to Service Connection hierarchy. This hierarchy covers everything from the physical hardware or virtual data center (like Amazon's EC2) that creates machine instances to the services and connections between services that make user and application transactions possible, and the outputs and storage requirements and maintenance of those services.
A hardware component is either a physical or logical (virtual) element that we care about in terms of providing a system, storage, network, power or other resource.
Physical examples included a hardware chassis, power supply, motherboard, CPU, RAM sticks and network cards, as well as many other types of physical Hardware Components.
Virtual examples could be as simple as an all-encompassing generic hardware component that may wrap all of a virtualized machine vendor, like Amazon's EC2, so that all functions for creating system, storage, floating IPs, load balanced addresses and other resources would come from a single virtual hardware component. Or, many virtual components could be created to give a sense of the different aspects of the virtual data center's resource creation. This is especially useful if they have a number of resources to track, such as remaining machines of various types, or storage, in a particular region or data center, since tracking the volume of resources available on Hardware Components is important to understanding how many more resources can be allocated, for regional and vendor specific capacity planning.
Hardware components have a parent, which is the hardware which they belong to. For a system, the parent resource would typically be a chassis, which would contain children like power supplies, a motherboard, disks and fans, among other root level children that might live in a chassis.
Then the motherboard would contain children Components, such as the CPUs and RAM sticks. Saving each stick of RAM as a child of the motherboard has the advantage of being able to monitor each stick, and be able to record how it is functioning, ECC error rates and other information, and will aid in diagnostics of hardware when hardware maintenance is required. Any Component specified as part of a Set of Components can then have data tracked against it's actual Instance, so creating a detailed specification allows us to monitor each Component individually, and makes maintenance tasks and tracking history of Components easier.
Each element of hardware that is important to monitor or configured should be accounted for as a separate element, so it is can be tracked independently and our data closely models reality as is useful. Our goal is to model reality, in as much detail as provides as value, so that we can easily enforce that reality matches our data model.
If a Hardware Component has an external shell, and this corresponds to it's rack space usage, it is given a Rack Unit height value. All chassis' would contain a Rack Unit (RU) height, for the space they take up when mounted in a rack. Combined with the Hardware Set Instance's Location, and Rack Unit Mount Height, we have specified the exact position of this hardware for easy directions to physically finding it.

One important aspect of hardware is that Components connect together to other Components, both inside the same Hardware Set (such as disks to the drive controller) and to other Hardware Sets (such as NICs to switches, PSUs to power strips, Fibre Channel to SAN switches, etc). Instead of making these Hardware Components, Ports are special and attach to Hardware Components, but are considered separate.
Hardware ports specify a media type (like 110 Power (TODO(g): What's this media connector called?), RJ-45, Fiber Channel or DB9), and whether they are a Provider, Consumer or Bi-Directional, to assist us in understanding which port is providing power and which is consuming power, or which is providing the source KVM signals, and which source is consuming KVM signals to pass on to a remote user. Finally the type of resource they are providing (like 110 Power, 220 Power, Network, Storage, Serial, Video, Keyboard, Mouse, etc).
Combined with the Location of the Hardware Set Instance's that these Ports connect, finding connected hardware should be a repeatable process with no areas of confusion. Because REM is a TSA system, it is critical that information is accurately entered and kept accurate on any changes to physical hardware. In order to automate reality, we must ensure our data map of reality is accurate or unintended consequences will occur.
A Hardware Set is the sum of all the Components and ports that are under the root Hardware Component, such as a system chassis, which include's the systems power supply, the port the power supply receives it's power from, the motherboard, CPUs and RAM on the motherboard, the drive controller (if considered a separate Component from the motherboard), and it's ports that will connect to the disks that are children of the chassis.
The Hardware Set is a specification for a certain make and model of hardware, like a Dell 2850 server, or a specific Cisco 5000 series switch. Each different configuration, whether it has a different RAID card, or more RAM, should have it's own Hardware Set. Duplicating and modifying previously specified Sets should make minor configuration changes easy, and we typically want to try to minimize variances in hardware specifications anyway, so this method encourages thoughtful use of different hardware configurations as the differences of maintenance and work involved to support more configurations is made more obvious, and when desirable the correct path for automating each variant properly is enforced under the REM system.
Functions are written against this Hardware Set, as everything in this Hardware Set is fixed, so Functions are not needed to be written against a specific Component or Port, which would be over-designed and lead to more duplication and organizational work, with no greater ease of maintenance or understanding, because only the grouping of all the Components together can be tested, so Functions should be written against the entire group of Components in the Hardware Set.
When similar Hardware Sets can share code, the scripts can simply be duplicated without change, but all Hardware Sets required their own Function scripts, because no absolute compatibility exists between any two different specifications of hardware, as a single difference in RAID controller versions could break many functions that rely on one implementation and do not work with the other. So each Hardware Set has it's own copy of Functions, and their corresponding scripts to ensure assumptions about similarities do not cause operational failures.

A Hardware Set Instance is the first usable data construct in this hierarchy so far. Before this, things have been specified in general, but this is a unique instance of a specified set of Hardware Components and Ports.
A Hardware Set Instance has a Location, which is hierarchically specified (North America -> California -> Sunnyvale -> Data Center Name -> Cage Number -> Rack Row), and then given a Rack Unit height from the bottom of the rack position being RU0. So a Hardware Set Instance may be positioned at RU20, half-way up a rack, and it's root Hardware Component, a chassis, has a 10 Rack Unit height value, so the Rack Unit area between RU20 and RU30 is taken up by this Hardware Set Instance.
When connecting Ports to other Ports (always the case), the Hardware Set Instance must be used, as it is the actual device with the actual ports that connect to some other actual device's actual ports. These could be virtual, and this could be useful in describing how network peering arrangements are set up, where third party network sources are created as virtual Hardware Set Instances, and their ports connect to the demarcation ports of our equipment, or the equipment of our vendors that we are aware of and care about tracking.
Because Ports specify whether they are a Provider, Consumer or share resources Bi-Directionally, then a dependency graph can be created for monitoring and alert suppression purposes, as well as capacity planning and as sources to collect information against when monitoring, graphing, and mapping usage for bill comparison.
This is an abstraction as a method for how to interface with a Hardware Set. The Megavisor sits on top of any other kind of management for the hardware, so if a hardware hypervisor exists for creating virtual instances (like the IBM Blade LPARs), the Megavisor controls the hardware hypervisor. Similarly if hardware has a software hypervisor (like VMWare's ESX or Xen), the Megavisor also manages this to create traceable instances. Finally if hardware is simply raw hardware, the Megavisor controls this the same way.
The Megavisor is simply a wrapper for named scripts, Functions, that control a specific Hardware Set. A Hardware Set may have more than one Megavisor that could control it, if different scripts provide a different kind of functionality. This will be more useful on a regular basis for creating a new version of a Megavisor, so the old version still functions on instances it controls, while the new Megavisor set of Functions is being tested, and then instances are migrated to it.
REM is designed to be upgraded, so every area works to provide mechanisms to go through development, QA, staging and finally make it into production, both for REM control scripts and changes, and for the actual operation environment, since both are critical to a smooth running operation.
A platform is basically an operating system installation version. This is a label for a specific brand and version of operating system, or different builds and patches of an operating system.
As software is updated, patched, or modified, new platforms will be created so that they can be tested, approved for production, and finally machines can be brought up in production usage with the newly certified platform.Packages are the same no matter how they are categorized or installed. All packages contain a sequence of things to install, by the installation path and type (like an RPM, checking out of source control like Perforce or SVN, or less desirable ways like rsyncing or copying from a network location like an HTTP or FTP server).
Packages that installed on a Platform are the basic packages required to boot up the operating system, control the devices (like storage and network), and do basic client services (like DNS, mail client, and mount network storage).
Packages that provide services (like NFS servers, web servers, application servers, central account management, etc), will be the same kind of package but should be listed as a Service Package, not a Platform Package.
Packages list all their inputs and outputs. If a package, like Apache, listens on a TCP port for the HTTP protocol, with a default of port 80, then this is specified in the Package Interfaces, as a Incoming Transaction Interface (Bi-Directional communication, listening for connectors). Additionally if a Package writes to a log file, an output Interface is created, that specifies the destination path default, and default rotation, retention delays (local and global), and backup frequency, so that all output is also going to be dealt with in a way that takes care of local (local disks) and global (long term storage) resource constraints and cost.
Packages also specify what Connections they make to other Package Interfaces. For an example, a Syslog Client package has a Connection that is made to a Syslog Server Interface (UDP or TCP Listening Message Interface).
Different kinds of Interfaces are:
Package Functions also contain everything needed to configure a machine so the package's system services can automatically start up (such as Apache's httpd service), and how to start, stop, restart, reload configuration files and refresh rotated log files, or any additional control features such as clearing queues, resetting server components, or whatever other administration tasks are needed for the installed contents to actually function on the machine.
For a Package, whether Platform Package or Service Package, to have it's executables actually do anything over a network a Service needs to be defined which mounts the Package (Services can mount Service Packages or Platform package's Interfaces) interfaces as a Service Interface, which will then allow configuration of a machine resident firewall (like iptables) to lock down any incoming connections to only those specified in the Service mounted packages, so that packages do not listen to actual wire traffic unless the Service definition explicitly states that they can, and how.
Packages define their Monitors, so that monitoring is tightly coupled with the package services that need monitoring. All Packages that are installed on a Machine are monitored, whether they have Service Mounted Interfaces or not.
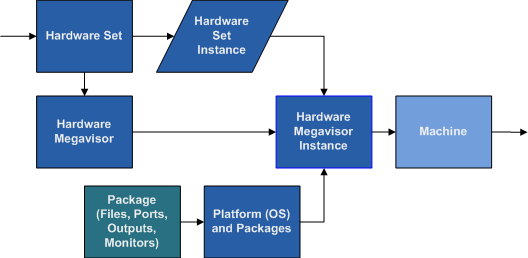
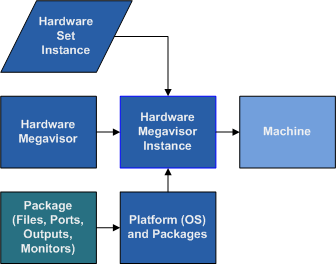
A Megavisor Instance is the combination of a Hardware Set Instance and a Platform.
This gives us our first concept of a distinct system element that we can use. It is a specific Megavisor Instance, so has computing and memory resources, and some sort of storage that could take the Platform operating system and Packages.
This is a fairly thin layer of abstraction, but important as it is where all the distinct pieces come together to wrap any kind of virtualization and hardware that exist at a lower level.
The Machine is the full concept of a system. At this point all other aspects, such as what operating system it runs, whether it is a physical machine or a virtual instance, whether we own the hardware or are renting it from a vendor have all been abstracted away. This is merely a machine resource that has a certain amount of CPU power, memory, and is running on the network with very basic services set up, and is completely locked down in terms of any incoming network connectivity.
A machine without any Services on it should be maximally locked down, only connecting out to send it's routine administration mail, syslog events, and any backups of log files for the basic system functioning.
Monitoring is also enabled, which is the only exception for the un-configured machine. If the REM system knows about it, it is being monitored to make sure it is still functioning as it should be and is ready to take on a Service when it is needed.

Storage is the encapsulated sum of everything needed to manage the physical or virtual elements, whether local or remote, that allow us to mount a device, or series of devices, onto a machine and ultimately onto the file system path for writing files, or not mounted if raw device usage is preferred.
The number and type of the volumes and the functions to manage those volumes are wrapped in the Storage Volumes and Storage Handler Stack, respectively.

Every Storage has a Handler Stack, which is a hierarchy of Storage Handler's, which are named sets of Functions, such as for the ext3, XFS, ZFS or JFS file systems, or the DRBD network RAID 1 layer, the Linux or Veritas Volume Managers, and local disk or Amazon Elastic Block Storage (EBS) or SAN mounted volumes. There are many options at several layers for creating a usable storage device, and the Storage Handler Stack tries to make wrapping these an easily repeatable process.
A Storage Handler Stack for an Amazon EC2 machine might look like this: EBS -> DRBD -> LVM -> ext3.
This means an EBS volume has been created and assigned to the machine, then a DRBD network RAID1 layer was created on it to keep it in sync on another machine, then the Linux Volume Manager was assigned to freeze and unfreeze volumes, and ext3 for the file system.
When running any Functions over Storage, which is how things are done with Storage, Function scripts are called in order, first from the top of the stack (ext3) to the bottom (EBS), and then back from the bottom (EBS) to the top (ext3), as all Storage Handler Functions have both an Entry Function and an Exit Function. This allows atomic operations on Storage, taking account many operations that may need to happen for each layer in the Storage Handler Stack.
For example, to run a Snapshot command on the EBS volume these would be the steps for the above stack:
This creates a consistent Snapshot, because no I/O can occur on the device until the LVM is unfrozen, making EBS Snapshots atomic.
In this way, everything for Storage from Requesting (for EBS or SAN controller devices), Configuring (creating connecting devices, formatting), doing Snapshots or backups, Diagnostics or any other device related operations can be performed.
A Storage Volume is the individual volume, possibly of many, that stores data for the Storage. Many volumes may be used in a RAID configuration, with spares, or any other kind of configuration that the Handler Functions will wrap.
The Storage size is the final device size for the storage, after all the work has been done to configure it for use. Storage Volume size is the raw size of this storage before it has been configured for use. The sum of all Storage Volume sizes may be much larger than the Storage size to create redundancy.
Backups of all volumes will be done all at the same time, and consistently, if set up and scripted properly, so that a complex Storage made from many Volumes will always be able to be recreated from the last snapshot if the running storage fails it's correctness or functionality tests. If the restore from Snapshot fails, then earlier Snapshots can be used until one passes and the Storage can return to use. How to handle this is up to the implementer's scripts, but the emphasis is on automatic ensurance that the latest good data is always present and available on the required Machine.

The Service is the most important concept in REM. A Service defines everything a class of machine will need to do to perform it's job. This includes:
Any given Machine is only serving one Service, which, on top of the basics of the Platform, specifies all the things that need to be installed, as also how they connect with other services, so that all configuration files can be automatically filled with template data, as long as the configuration files are properly formatted with REM Service Interface and Connection Template Formatted variables.
Services are versioned, with "parent" Services as earlier versions of themselves, and a serial version number, so any changes go through the deployment process (Dev, QA, Staging, Production), so no Service changes result in downtime once it is finally being Canaried into Production, Service Levels can be applied to see if too large of a performance degradation is present, even if the functionality is correct.
See Platform Packages for a description of a Package. This Package is just defined for the Service, which is the specific type of Machine, by function, instead of in Platform, which is the operating system and basic client and driver Packages.
Like Platform Packages, these Service Packages have all the Interfaces and Connections specified inside them, and they will be monitored, and logs rotated and retained for the specified time, and backups created, even if they are not mounted by the Service to be connected to other Services.
Once the Interfaces and Connections have been specified in the Service, for the given Packages, then the Machine can have the mounted ports made available in the Machine resident firewall.

A Service Interface takes a Package on a machine, whether it is a Platform Package or Service Package, and maps the Package Interface to a Service Interface, which is named and is the target of a Service Connection, and the default recommendations for values like port number, are specified by using the default or assigning a different value.
The Service Interface represents a way to allow incoming network traffic to the Service Machine, and allows dependency graphing of all of our Services, for Alert Suppression, so that the supplying Service is known to be a dependency for receiving Service.
This is an outgoing connection from a Service on the running machine, to another Service (probably on another Machine, but not enforced).
Between the Service Interface and the Service Connection, we can populate our configuration files with REM Template Formatted Variables which will be automatically populated with the data specified in the named Service Connections and Interfaces, so that configuration is always correct, and Services can be re-organized in their specifications, and configurations will remain properly configured.

Service Levels deal with the amount of Machines running for a particular Service, in a particular Location. Locations may need different amounts of Machines to provide the best service at the best price point, as well as different Machine requirements (Hardware Sets).
A basic Service Level might be "Minimum of 5 Machines in Site Location 0", or "Maximum of 50 Machines in Site Location 0". These would ensure there are always at least 5 Machines in a Site Location 50.
Location's are abstracted by order of preference, as Site Locations. Site Locations have an order of precedence which is used for specifying the Location order, so that given Location A, B, and C, they can be ordered:
This means we could say there are:
Now if Location A has a catastrophe, such as loss of power to the data center, we can re-order the Site Locations like such:
And so 5 Machines would be created in Location B (Site Location 0) and 1 Machine would be created in Location C (Site Location 1).
If Location A comes back, it could be set to Site Location 2, and no Machines would be created or removed, or it could be re-inserted into Site Location 0, to restore the original order. This would add 5 Machines to Location A, and remove 4 Machines from Location B, and remove 1 Machine from Location C.
In this way we can deal with losses of Locations for disaster recovery, as well as specifying different rules for how to scale in a given Location.
Minimum and maximum Machines is a very simple Service Level case.
More interesting cases would be for a Service Level will be directed at the duration of a HTTP monitoring request for a specific Service Interface (specified against the Package RRD Field, with a Monitoring Rule). If the duration of this HTTP request is over the given amount, such as 50ms, then more Machines should be added to the Service in the specified Site Location, based on the Service Level Rate Change Rules (to ensure increases or decreases are not performed too rapidly, which may cause service interruptions).
Service Levels can also be assigned by the Location (not Site Location), or by a Hardware Set profile, because different Hardware Sets and Locations may have different Service Level parameters, and just because Location A is down, does not mean that Location B will ever be able to serve the same Service Level. For instance, a Location that never gets better than 100ms round-trip packet times will never meet a 50ms Service Level requirement, so when Service Levels depend on a Hardware Set or Location, they should be specified as such.

Monitoring in REM is defined in Packages, so that the Monitors are tightly coupled to the installed software they are supposed to monitor.
Monitoring starts off with local or remote scripts which collect data from our Machines. Every Machine runs a Local Monitor, which collects and stores Monitoring data, and buffers it for a Monitoring Collector to come pick it up and store it in RRD (Round Robin Database) files.
RRD files are perfect for storing time series data, and monitoring data is very useful to track as a time series. This is obvious for graphing typical performance metrics of CPU, memory and disk utilization, but it is also an excellent storage mechanism for service response times (like the duration of an HTTP request), or number of messages in the mail queue, which is data we might want to make alerts to take automated action on.
Storing time series monitoring data in an RRD allows us to test results over time, so we can test that 20% of the last 10 entries matched an Monitor Level setting, to make fuzzy monitoring possible, where a service is not merely working or not working, but is intermittently working, or working with a degraded performance.

Remote Monitoring works similarly to Local Monitoring, but Remote Monitors are run from a different Machine than the one being monitored, so that it can be tested externally.
The Local Monitor process on the Remote Monitoring Machine will still buffer the result data, and the Monitoring Collector will still come and pick it up and put it into the monitored Machine's RRD files, so the only difference is where the script is run.
Remote Monitoring is set up in degrees:
The algorithms to determine Near and Far Machines can be decided by the implementers, but by default will be a Machine in the same Location for Near, and a Machine in the next closest Location for Far.

A Monitor in REM is really a definition for how to collect information and store it into an RRD. RRD information is collected by running scripts on the local Machine, or a remote Machine, that returns a dictionary that maps to named columns in the RRD. When the scripts are run, the dictionary results are returned for a given RRD, and then the results can be stored in the specified columns for the time period when the monitor was run.
With this, any kind of information can be collected about a Machine and it's performance and running state, as well as whether it's programs are working properly, depending on the result.
All RRD data that is defined can have Monitor Graphs created, and all default RRDs have default graphs already specified. The frequency in which a graph is created from data, and what layout of that graph is specified in the Monitor Graph definition, for a given Monitor.
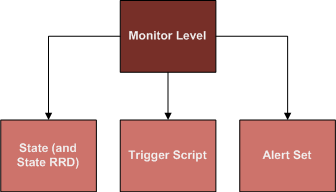
A Monitor Level is a wrapper for a script that runs against a specified RRD field or Package State value.
Monitor Levels are comparable to Service Levels. This is the "Monitor Level Agreement" that defines when a Monitor is needs to do something. When the Monitor Level's conditions are not met, then nothing needs to be done or recorded about the things that are being monitored. Some Monitor Levels will be solely for the purpose of continually recording data by writing it into State and an RRD file for other Monitor Levels to query and use.
A Monitor Level is attached to a single Monitor, and does a single thing. It is a condition, that if true, will either set a State (and RRD file), a Trigger, or an Alert. Each of these produces a different immediate result, some result in actions, other just store a value. Monitor Levels can be influenced by other Monitor Levels, by using already set State variables to layer knowledge.
Monitor Levels are named, and all Monitor Levels with the same name, attached to the same Monitor, are run as a group, and all Monitor Levels specified are ANDed to produce the result. Only when all the Monitor Levels match their rules is the named Monitor Level actions taken.
A Monitor Level action is going to either set a State variable to a value (also saving an RRD entry for this State-value), set a Trigger variable to a value, or set an Alert to be active.
Each Monitor Level can specify it's own action, so when using multiple Monitor Levels of the same name on the same Monitor, many results could occur, or only a single Monitor Level could have an action set to handle all the work at once.
Monitor Levels can use State and RRD values as inputs, so they can read the results of other Monitor Levels and time series data from RRDs.
Monitor Levels that write results into a State variable, automatically also write that value into an RRD file, so those states can be tested over time. RRD files are made to be fixed size, so these files can be small if desired, but the ability to process time series data about our states is powerfully useful.
Monitor Levels have two scripts, a Condition script for determining the condition of this Monitor Level, and a Trigger Script, which is what to run if the Conditions on all the Monitor Levels of the same name are true.
State is stored against a Package Instance (on a Machine instance), a Machine, and a Service. Package Instance State is tracking the current state of a installed package on a given Machine, Machine State is tracking information about that Machine, and Service State is tracking information about all the Machines and Packages in the Service.
A Trigger is when a Monitor Level has a Trigger Script associated with it. If the Monitor Level's conditions are all active (for multiple Monitor Levels with the same name on a given Monitor, all conditions must be true for any of them to be true), then the Trigger Script will be executed.
An Alert is set when an Alert is specified in a Monitor Level. Any Monitor Level with an Alert specified, whose Monitor Level Group's conditions are all true, sets the specified Alert to true, so many Alerts could be set true from a Monitor Level Group.

An Alert is a named method of communicating about an issue. When an Alert is set, the goal is to let someone know about it, as long as it's dependencies are not alerting (automatic suppression).
Alerts with dependencies that have already alerted are suppressed for as long as the dependency is alerting. If the dependency stops being on alert, and this Alert is still active, then this Alert will begin it's communication.
Once an Alert Communication entry has been made, the Alert will keep trying to communicate until it receives an Acknowledgement. The Acknowledgement will suppress the Alert Communications for a time period (like hitting snooze for 10/30/60 minutes on an alarm), or can Acknowledge the alert completely, suppressing any more communications until the Alert has stopped being active for a long enough period of time to consider a new Alert being set to be a new Alert. This delay is specified in the Alert. If an Alert is acknowledged-with-suppression, and the Alert clears, but then activates again, the acknowledge-with-suppression is overridden, because the Alert's service is working intermittently. A forced time period suppression will be necessary to block repeats of intermittent Alerts, so as to highlight the problem is known.
Every Service has an Ownership List, which is a list of User Roles associated with this Service, and their users. Roles are given an On-Call Communication Sequence, which determines the order in which each User Role will be contacted.
User Roles are populated automatically by an on-call rotation scheduler, which has an ordered list of users in a User Role, and then creates a calendar of when these users are on-call for their User Role. An example User Role would be Mail On-Call, in which three administrators may be responsible for the mail service, and so each of them would be listed in sequence for the Mail On-Call. The On-Call Calendar is automatically populated based on the rules for when a given User Role goes on-call and comes off on-call. User's can move their On-Call times around with each other, and the schedule can be changed once it is automatically populate.
Users are notified by their Alert Communication method before they go on-call, and when they get off on-call, to reduce confusion. If there is an on-call task list to be performed, this can be set up to be emailed out by a script for each Service that explains things that need to be done with the service. Also any current Alerts that are active (even if suppressed, but not if their dependency is alerting), are sent to the email address of the newly on-call User Role member.
 Sites
Sites
A Site is a entire system of Services and Machines, which should contain everything needed to perform operations for a given organization or application set.
Typically a small or medium sized business will only have one Site. A large or enterprise business may need more than one Site.
The differentiating factor is whether different people will be taking care of these different Sites. Sites have their own user administration and alert escalation information. Different sites will contact totally different sets of people (as far as REM is concerned, it doesn't enforce any difference), so they need to be able to work in a way that doesn't conflict with each other, but still be able to share information authoritatively to be able to tightly integrate the different Sites.
Sites have Config tables which keep track of all the site-wide configuration details, as well as a State table which Monitors can populate about running data about the site.
At least one Hardware Component inside a Hardware Set, that is used for a Megavisor Instance will have a Location. Typically the root Hardware Component (chassis) will have the Location specified.
A Location is a self-hierarchy, in that Locations are children of other Locations, down to the rack or desk that a Hardware Component is installed in. The Hardware Component tracks it's Rack Unit Height, which is considered part of the location, but Locations do not track things vertically.
Location example:

This would track this Hardware Component down to the Rack. Any Location along the hierarchy can specify it's latitude and longitude coordinates (zip codes can be converted easily). These allow us to do distance tracking between locations. The Location entry which has it's latitude and longitude set and is closest to the final Location entry will be the latitude and longitude used for this Location.
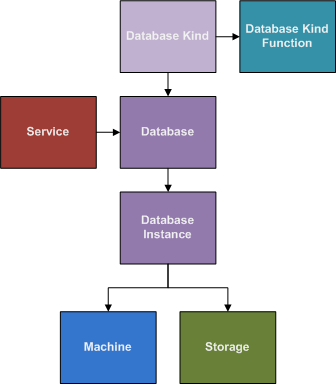
Databases are a special construct in REM, because databases have very special needs. A Database in REM is not necessarily a traditional database like MySQL or Oracle, though it is certainly meant to manage those systems, but any complex program structure that depends on persistent data, like an Exchange mail server, would also be considered a database. In contrast, a persistent storage requirement for NFS is not a Database, because there is not complex mechanism around the storage. The storage on an NFS machine needs to be persistent, but it doesn't also have to sync up to a program that has a number of expectations about the data beyond the data merely being present.
Databases also require replication, and perhaps sharding and table splitting (where different tables sit on different storage volumes for capacity or performance.
Databases are region specific, because they are required to have a certain level of response for clients that connect to them, so location is a major factor of automation of databases, and critical for keeping persistent storage attached to a Database Instance, even when the original Machine instance the database ran on has died.
A Database in REM, is the specification of a Database kind, and further specification of the Storage requirements, and Location requirements. Nothing beyond specification happens in a Database, things start happening once a Database Instance is created.
When a Database Instance is created, the Database Provisioning Script for that Database Kind will pick the best Machine instance available. This might be a Machine that is already running a read-replica Instance, but is being re-purposed as a write-master Instance because it has the right kind of storage and is most up-to-date. This kind of flexibility in selecting a Machine to purpose for a Service is typically not needed, but is in the case of Databases. Services that have this kind of requirement should be considered a Database, even if that is not how it is normally thought of.
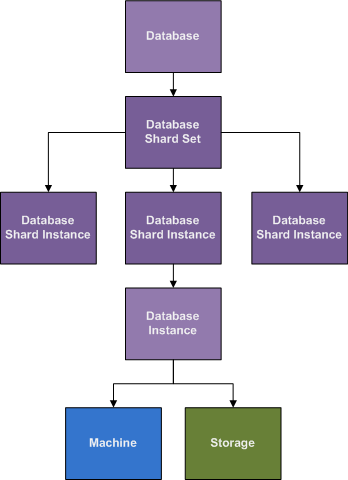
The one thing we should be able to assume about a Database that has grown enough to need sharding, is that it will probably grow more in the future and the current number of shards will at some point become insufficient. REM plans for this by giving several options to define how long to shard in the current shard configuration, and what to do afterwards. If left unattended, a properly configured REM installation should approach the limit of the current sharding strategy, and create more Database Shard Instances to automatically migrate to the next phase where more shards are required. Planning and scripting this must be tested by the implementer, as this has not been coded for in a general way yet, but the framework is there is automate this as well, and everything is currently in place to make it easy to switch from one configuration to another, while leaving the legacy shards in place, to continue to serve traffic for the older mechanism, if it is decided to partition the data at the point of shard size change (which makes this process much easier).

Properly configured Packages and Services will be automatically configured based on the Package Interfaces, the Service Interfaces (that mount Package Interfaces and define their actual values where Packages specify only default values), and the Service Connections that bridge another service to this Service Interface.
... ...To be continued...